With Snakemake, data analysis workflows are defined via an easy to read, adaptable, yet powerful specification language on top of Python. Steps are defined by "rules", which denote how to generate a set of output files from a set of input files (e.g. using a shell command). Wildcards (in curly braces) provide generalization. Dependencies between rules are determined automatically.
rule select_by_country:
input:
"data/worldcitiespop.csv"
output:
"by-country/{country}.csv"
shell:
"xsv search -s Country '{wildcards.country}' "
"{input} > {output}"
By integration with the Conda package manager and containers, all software dependencies of each workflow step are automatically deployed upon execution.
rule select_by_country:
input:
"data/worldcitiespop.csv"
output:
"by-country/{country}.csv"
conda:
"envs/xsv.yaml"
shell:
"xsv search -s Country '{wildcards.country}' "
"{input} > {output}"
Rapidly implement analysis steps via direct script and jupyter notebook integration supporting Python, R, Julia, Rust, Bash, without requiring any boilerplate code.
rule select_by_country:
input:
"data/worldcitiespop.csv"
output:
"by-country/{country}.csv"
script:
"scripts/select_by_country.R"
Easily create and employ re-usable tool or library wrappers, split your data analysis into well-separated modules, and compose multi-modal analyses by easily combining entire workflows various sources.
rule convert_to_pdf:
input:
"{prefix}.svg"
output:
"{prefix}.pdf"
wrapper:
"0.47.0/utils/cairosvg"
Being a syntactical extension of Python, you can implement arbitrary logic beyond the plain definition of rules. Rules can be generated conditionally, arbitrary Python logic can be used to perform aggregations, configuration and metadata can be obtained and postprocessed in any required way.
def get_data(wildcards):
# use arbitrary Python logic to
# aggregate over the required input files
return ...
rule plot_histogram:
input:
get_data
output:
"plots/hist.svg"
script:
"scripts/plot-hist.py"
The logic of production workflows can become complex by involving lots of lookups and dynamic decisions. Snakemake offers semantic helper functions for lookups, branching and aggregation that avoid the need for plain Python code as shown above, and allow to express complex logic in a human-readable and self-contained way.
rule plot_histogram:
input:
branch(
lookup(dpath="histogram/somedata", within=config),
then="data/somedata.txt",
otherwise="data/someotherdata.txt"
)
output:
"plots/hist.svg"
script:
"scripts/plot-hist.py"
Snakemake allows to define workflows that are dynamically updated at runtime. By defining so-called checkpoints, the workflow can be dynamically adapted at runtime. Further, input can be provided as Python queues, thereby enabling a workflow to continuously receive new input data (e.g. while a certain measurement is conducted).
rule all:
input:
from_queue(all_results, finish_sentinel=...)
checkpoint somestep:
input:
"samples/{sample}.txt"
output:
"somestep/{sample}.txt"
shell:
"somecommand {input} > {output}"
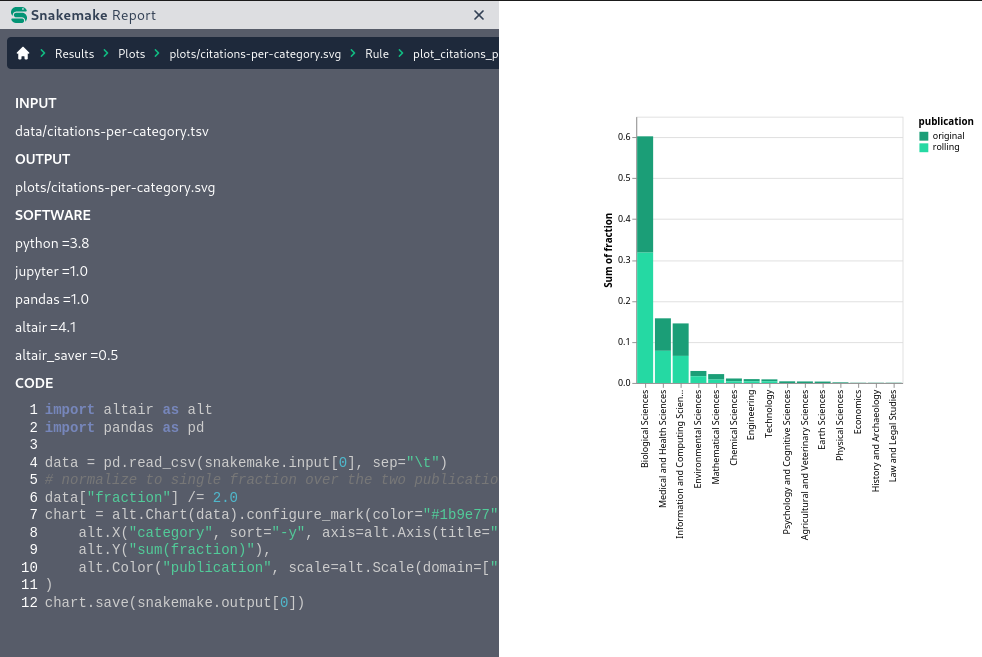
Automatic, interactive, self-contained reports ensure full transparency from results down to used steps, parameters, code, and software. The reports can moreover contain embedded results (from images, to PDFs and even interactive HTML) enabling a comprehensive reporting that combines analysis results with data provenance information.
Workflows scale seamlessly from single to multicore, clusters or the cloud, without modification of the workflow definition and automatic avoidance of redundant computations.

Snakemake is extremely flexible and configurable. Numerous options allow adapt the behavior to the needs of the data analysis at hand and the underlying infrastructure. Options can be provided via the command line interface or persisted via system-wide, user-specific, and workflow specific profiles.
executor: slurm
software-deployment-method:
- conda
latency-wait: 60
default-storage-provider: fs
shared-fs-usage:
- persistence
- software-deployment
- sources
- source-cache
local-storage-prefix:
/local/work/$USER/snakemake-scratch
Snakemake has a powerful plugin system that allows to extend various functionalities with alternative implementations. Via stable and well-defined interfaces, plugins can evolve independently of Snakemake, and mutual update requirements are minimized. Currently, execution backends and remote storage support is implemented via plugins. In the future, we will extend this to other areas, such as workflow scheduling, reporting, software deployment, and more.
Snakemake has a vibrant developer community that continuously improves the system. Every year, we conduct a 1 week hackathon with 40-50 participants. The 2025 hackathon at CERN was sponsored by the FAIROS-HEP research network. The 2026 hackathon at TU Munich is sponsored by BASF.

 affiliated project
affiliated project